





Here is the cleaned-up version of your note. I have applied Obsidian-specific formatting like callouts and improved spacing to make it more readable, while keeping every word of your original content exactly as written.
How Distilled Models Actually Work (Dec 2025 SOTA)
Summary
Summary of research into how giant AI models (Teachers) train efficient “Flash” or “Distill” models (Students).
Pre-training creates the “Brain.” Distillation gives that brain a “Personality” and “Logic Skills.”
1. The Core Concept: It’s Not Just One Method
Contrary to popular belief, there isn’t just one way to distill a model. There are two distinct methods currently in use.
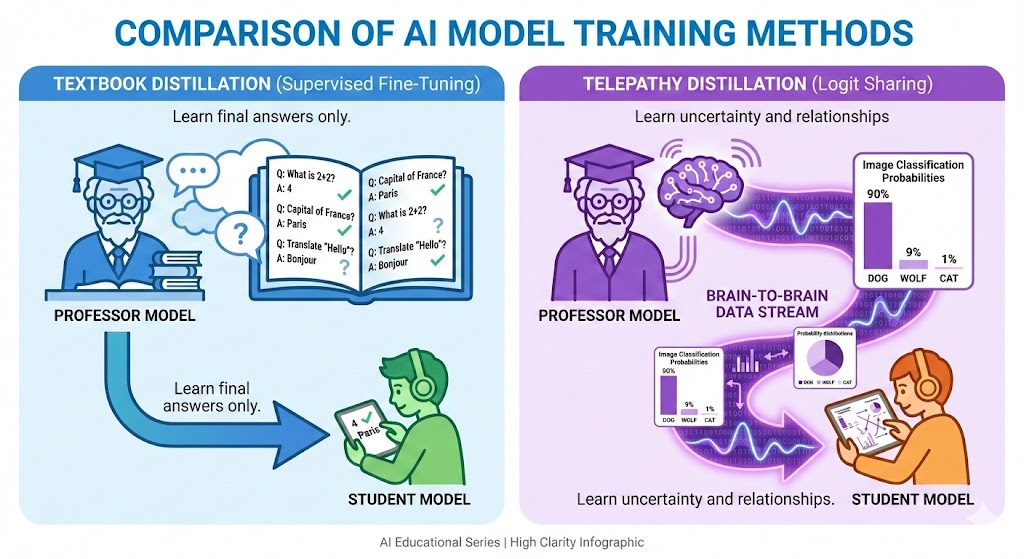
Method A: The “Textbook” Method (Supervised Fine-Tuning)
Used by: Open-source community (DeepSeek-R1-Distill, Alpaca).
Analogy
The Student reads a textbook written by the Professor.
- The Process: The Teacher generates questions and answers. The Student reads them and learns to mimic the output.
- Limitation: The Student sees the final answer, but not the “intuition” behind it. It’s a “Black Box” transfer.
Method B: The “Telepathy” Method (Logit-based Distillation)
Used by: Google (Gemini Flash), OpenAI (GPT-4o mini).
Analogy
Plugging the Professor’s brain directly into the Student’s.
The “Dark Room” Explanation:
- Textbook Method: The Teacher points to a picture and says “This is a Dog.” The Student learns 100% Dog.
- Telepathy Method: The Teacher shares its internal probabilities (logits):
“I am 90% sure this is a Dog, 9% sure it’s a Wolf, and 1% sure it’s a Cat.” - The Gain: The Student learns the relationships between concepts (Dogs ≈ Wolves ≠ Cars) and absorbs uncertainty.
2. How the Training Data is Created (The “Curriculum”)
It is no longer just “a static list of a million prompts.” The process has evolved into Active Coaching.
Phase 1: Synthetic Expansion
The Teacher isn’t just answering; it is creating the test.
- Human Seed: 50k hard math problems.
- Teacher Mutation: “Generate 100 harder variations.”
- Outcome: A huge synthetic dataset of high-complexity problems.
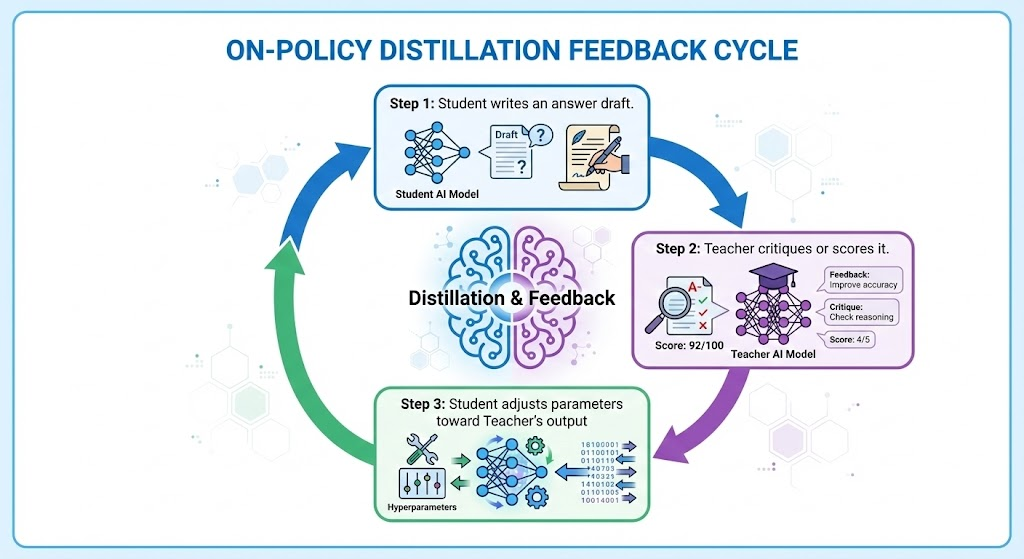
Phase 2: On-Policy Distillation (The Feedback Loop)
- The Student Tries: The baby model writes its draft.
- The Teacher Critiques: A Pro model scores or corrects it in real-time.
- The Adjustment: The Student’s brainwaves (logits) are aligned to the Teacher’s.
3. Quality vs. Quantity: The Numbers
- How much data? Surprisingly little.
- DeepSeek-R1-Distill: ~800,000 reasoning traces.
- Gemini Flash: ~1–5 million high-quality instructions.
- Why? The Student already “read the internet” (pre-training).
Distillation is just the Master’s Degree in logic.
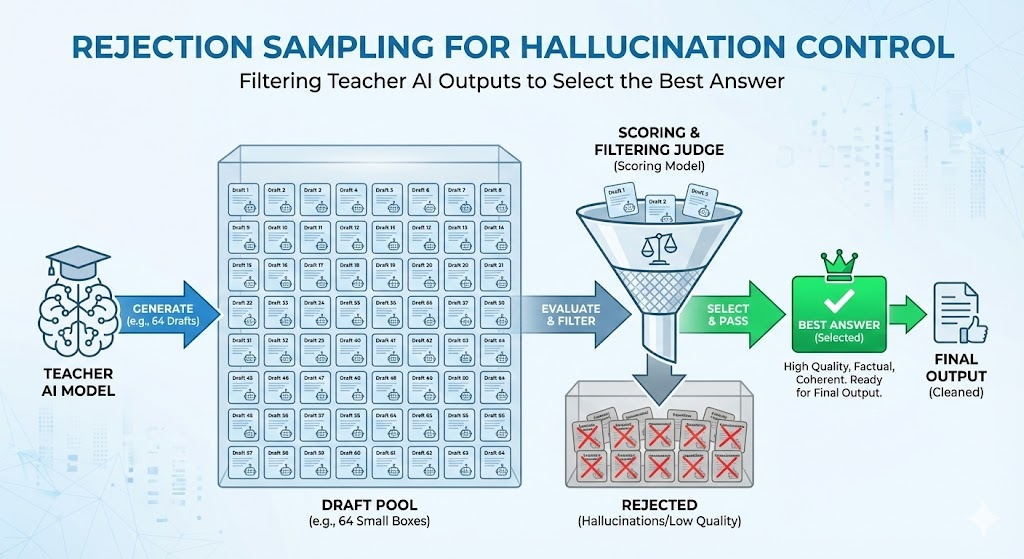
Dealing with Hallucinations (Rejection Sampling)
- The Quiz: Teacher attempts a problem.
- 64 Drafts: Multiple possible answers.
- The Judge: A compiler or reward model grades.
- Filter: Only the best-scored output becomes training data.
This deletes hallucinations before they infect the Student.
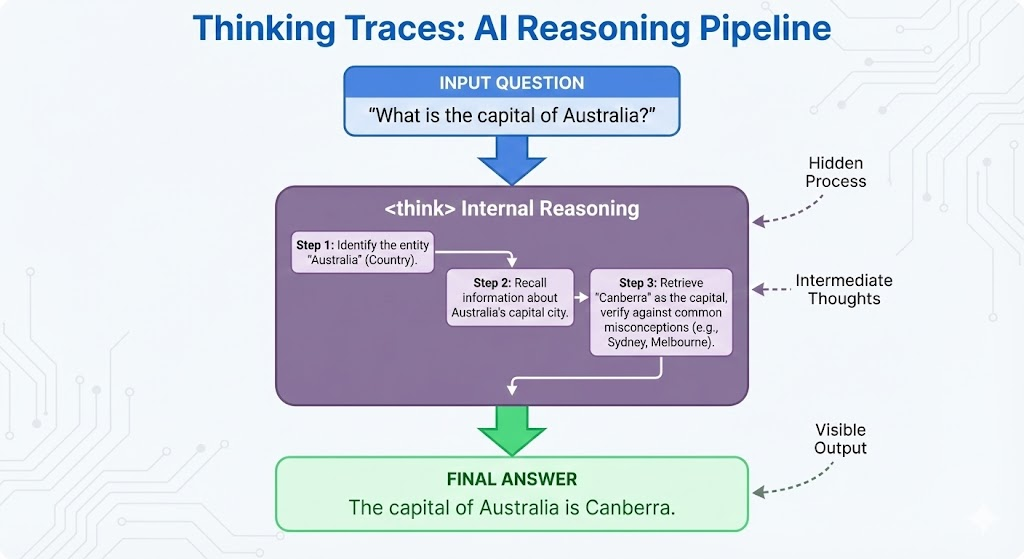
4. The Secret Sauce: “Thinking Traces”
In 2025, models don’t just learn the answer — they learn the internal monologue.
The datasets explicitly embed <think> traces:
{
"User_Prompt": "I have 3 apples. Ate one. Bought two. How many?",
"Teacher_Output": "<think>\n Step 1: Initial state = 3.\n Step 2: 3 - 1 = 2.\n Step 3: 2 + 2 = 4.\n </think>\n Answer: 4"
}
The Student learns how to pause, plan, and reason rather than blurting.
5. Stopping the “Infinite Loop”
How do we stop a model from thinking forever?
- Smart Way (Stop Tokens):
</think>becomes statistically likely. - Forceful Way (Repetition Penalty): Ban looping words.
- Dumb Way: Hard token limits.
6. Introducing Nested Learning (2025–2026)
A new paradigm from Google Research for continual learning, memory, and self-improving models.
The Problem it Solves
Modern LLMs have two weaknesses:
- They forget old skills when learning new ones — catastrophic forgetting.
- They can’t truly self-upgrade the way a human brain does over time.
Nested Learning claims these limits are artificial.
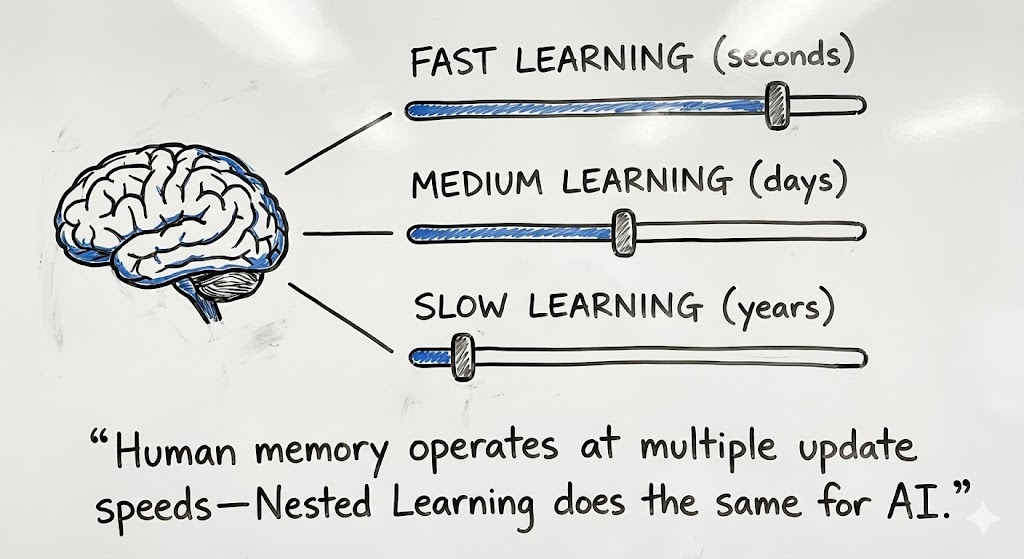
The Big Idea (Human Brain Analogy)
Humans learn at multiple frequencies:
- Some changes happen instantly (short-term memory).
- Some changes consolidate overnight.
- Some skills become permanent.
Nested Learning argues an AI should do the same. Instead of one giant brain with one update rule, a model should be seen as:
A stack of smaller brains nested inside one another — each learning at its own speed.
Each “brain” is a tiny optimization problem:
- It has its own memory.
- Its own update schedule.
- Its own context window.
Result: models learn new skills without overwriting old memories.
Why Current Models Forget
Standard training treats:
- Architecture = “a neural net structure”
- Optimization = “the training rule”
Nested Learning says those are actually the same thing. They are both learning mechanisms. We just didn’t see the layers. By synchronizing them, models become continual learners rather than one-shot products.
A Useful Analogy: GPU Clock Speeds
Imagine each internal module has its own “update frequency.”
- Fast modules adapt quickly (in-context learning).
- Slow modules stabilize long-term memory.
That creates a continuum memory system instead of a binary:
- Transformer attention = short-term scratchpad
- Feed-forward weights = long-term memory
Now we get a spectrum of memories rather than two buckets.
Why This Matters for Distillation
Distillation today teaches reasoning but does not let the small model keep learning.
Nested Learning offers:
- multi-level memory
- multiple learning timescales
- self-modifying modules
This means a distilled Student could keep improving — without retraining from scratch.
The Formula
Distillation = Start Smart
Nested Learning = Keep Growing
Hope: The First “Self-Modifying Student”
Google’s proof-of-concept architecture is called Hope.
- Builds on Titans architectures (surprise-based memory).
- Adds infinite nesting levels.
- Can optimize its own memory.
- Handles ultra-long context reasoning (needle-in-a-haystack tasks).
Hope outperforms:
- Titans
- Samba
- Transformers
- Mamba-style recurrent models
Because it can store information at multiple frequencies like a biological brain.
Why This Is a Paradigm Shift
Nested Learning:
- Unifies architecture + optimization.
- Enables continual learning without forgetting.
- Makes memory a frequency spectrum rather than two buckets.
- Suggests LLMs can become self-improving systems.
In other words:
Pre-training gave us intelligence.
Distillation gave us logic.
Nested Learning may give us plasticity.
A model that remembers, consolidates, and adapts — instead of rebooting every training cycle.
7. Where This Leaves Us (2026 Outlook)
Three tiers of evolution seem clear:
| Tier | Description | Outcome | ||
|---|---|---|---|---|
| Tier 1: Pre-Training | Read the Internet | Build the brain. | ||
| Tier 2: Distillation | Absorb Reasoning | Clone a master’s thought process. | ||
| Tier 3: Nested Learning | Learn Forever | Stop forgetting. Start self-improving. |
This is the closest step we’ve taken toward:
- persistent memory
- adaptive reasoning
- human-style learning plasticity
Or said differently:
Distillation makes a Student brilliant.
Nested Learning keeps the Student growing for life.