





Summary of: Recursive Language Models in ADK - Google Cloud / Community Articles - Google Developer forums
Overview
Abstract
Recursive Language Models (RLMs) are a new AI architecture designed to process massive amounts of information by breaking tasks into smaller recursive sub-tasks. Instead of forcing all data into a fixed context window, RLMs treat data and prompts as objects that can be navigated, analyzed, and modified through recursive calls.
This approach allows models to handle arbitrarily long inputs and outputs while reducing the token limitations that traditional LLM agents struggle with.
What does “Recursive” mean?
At its simplest, recursion is a process where something refers back to itself or repeats the same action on a smaller and smaller scale until a goal is reached.
Think of it as a “problem that contains smaller versions of itself.”
Simple Definition: Recursion
Recursion is the process of solving a large problem by breaking it down into smaller versions of the same problem. In RLMs, the “parent” model delegates tasks to “child” versions of itself, allowing it to process infinite data without filling up its immediate memory.
🧩 The Core Problem: Context Constraints
Traditional LLM Limitations:
- Fixed Windows: Must fit all input inside a specific context window.
- Tokenization: Everything is converted into tokens, which are finite.
- Information Loss: Summarizing or compressing data inevitably loses nuance.
- Scale Issues: Cannot reliably process very large documents or datasets.
Even coding agents with tools (like grep or Python) still pull results back into the main context window, consuming tokens for each tool call and eventually hitting a hard limit.
💡 Key Insight: Symbolic Recursion
In a recent discussion, Omar Khattab explained that RLMs introduce a fundamentally different concept: Symbolic Recursion.
What is Symbolic Recursion?
Instead of converting every sub-call into tokens, RLMs store information in symbolic variables. This allows sub-calls to operate independently without flooding the main context window.
The Result:
The main model acts as an orchestrator. It manages tasks but does not need to directly read or write every single intermediate result.
Tweet: x.com
⚖️ RLMs vs. Traditional Coding Agents
1. Prompt as a Symbolic Object
- Normal Agents: The user prompt is just tokenized text. The model reads and manipulates it freely.
- RLMs: The prompt becomes a structured symbolic object. The model cannot simply “copy” large pieces; it must write recursive logic to analyze it, forcing structured reasoning over brute-force reading.
2. Recursive Delegation
- Normal Agents: Sub-agents consume tokens. Each nested call increases the parent’s context usage.
- RLMs: Can spawn unlimited recursive sub-calls. These do not expand the parent context. Results are passed through symbolic references, allowing scaling to massive tasks.
3. Recursive Output Construction
RLMs can build output recursively:
- Generate extremely large responses.
- Store output in variables.
- Recursively edit or critique drafts.
- Produce final output only after validation.
🔍 Simple Analogies
📚 The Librarian
- Traditional LLM: Reads an entire book before answering a single question.
- RLM: Acts like a head librarian who sends assistants to summarize specific chapters, reviews those summaries, and combines them into a final answer without ever reading the full book personally.
🏢 Manager and Worker
- Traditional Agent: A manager trying to do all the work personally while flipping through a massive pile of notes.
- RLM: A manager who delegates work to specialized teams recursively and only supervises the high-level results.
💻 Software Functions
-
Traditional LLM: Runs like one single, massive, monolithic function.
-
RLM: Runs like a program with recursive functions calling smaller helper functions until the problem is solved.
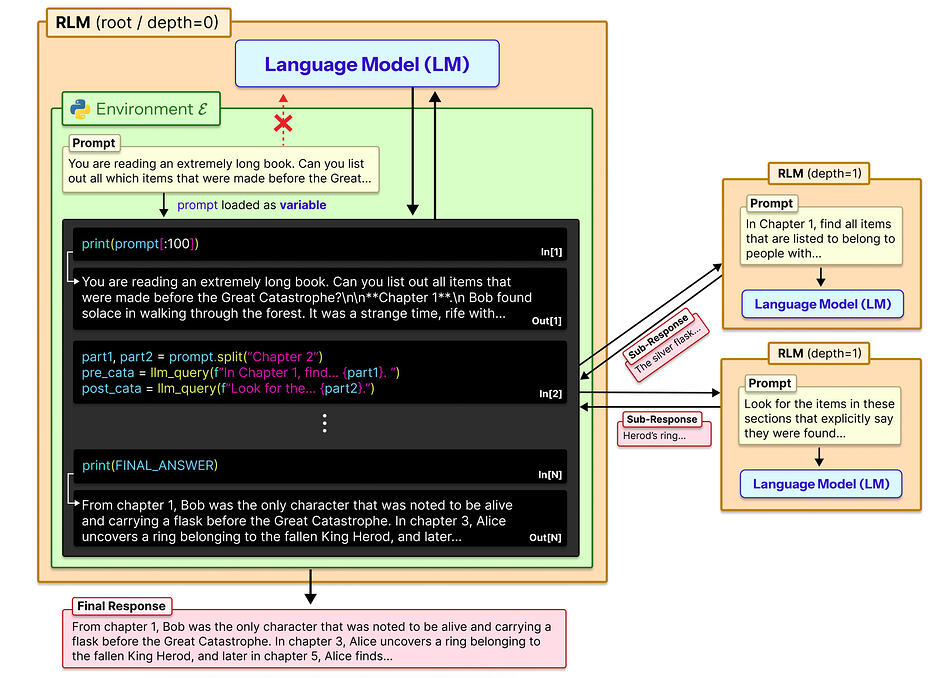
⚠️ Example: The 10-Million Token Summary
Scenario: A user pastes 10 million tokens of documentation and asks for a detailed summary.
- Traditional Agents Fail: They cannot load the dataset, must repeatedly compress data, and information loss is unavoidable.
- RLM Solution:
- Breaks documentation into chunks.
- Assigns recursive summarization tasks.
- Combines results hierarchically.
- Produces a massive, reliable summary.

🚀 Why This Matters
RLMs introduce a new scaling method for reasoning and context handling.
Potential Benefits:
- Massive Context: Understanding long-form data without loss.
- Reliable Reasoning: Better logic over large datasets.
- Structured Orchestration: More efficient agent workflows.
- Efficiency: Significantly reduced token waste.
🛠️ Relationship to Google ADK
Google’s Agent Development Kit (ADK) adapts RLM concepts into practical systems by enabling:
- Lazy loading of context from multiple data sources.
- Parallel execution of recursive tasks.
- Debugging and monitoring of specific sub-calls.
- Real-world integration with agent workflows.
🌙 Mental Model Summary
RLMs shift AI from:
“Read everything, then answer.”
To:
“Strategically explore information through recursive delegation.”
🧩 Limitations & Open Questions
- System Complexity: Much harder to build and maintain.
- Debugging: Recursive logic can be difficult to trace when things go wrong.
- Overhead: Performance hits if the recursion is poorly designed.
- Adoption: Still an emerging architecture with limited production use.
💡 Personal Intuition
RLMs feel less like a “chatbot” and more like:
- Operating systems managing various processes.
- Distributed computing workflows.
- Human research workflows (where we break big problems into small tasks).
They treat information like a navigable environment instead of a single, flat prompt.